非线性SVM
上一节的算法针对的是输入空间存在线性判别面的情况。对分类面是非线性函数的情况,理论上应将输入空间通过某种非线性映射,映射到一个高维特征空间,在这个空间中存在线性的分类规则,可以构造线性的最优分类超平面。但是这种方法带来了两个问题;一是概念上的问题,怎样在如此高维的空间中找到一个推广性好的分类超平面;二是技术上的问题,如何处理高维空间中的计算问题。
前面我们把寻找最优超平面最终归结为其Wolfe对偶问题,一个很重要的副产品就是找到了一个克服维数灾难、解决技术上问题的绝好方法.如果数学上可以找到一个函数K : (Rn, Rn) -4 R,使得K(xi,xj)就等于xi,、xj在高维特征空间中的映射的点积,那么用K(xi,xj)代替Wolfe对偶问题中为xi和xj的点积即可,计算量将会大大减少。事实上确实存在这样的函数,Vapnik称之为卷积核函数,于是我们只需在输入空间中计算卷积核函数,而不必知道非线性映射的形式,也不必在高维特征空间中进行计算。
通过上一节已经看到,线性SVM是以样本间的欧氏距离大小为依据来决定划分的结构的。非线性SVM中以卷积核函数代替内积后,相当于定义了一种广义的距离,以这种广义距离作为划分依据。也许并不一定所有的学习机器都要以样本间距离作为划分依据,但是对于面临的很多问题来说,把距离近的样本划分在一起确实是理所当然的。
我们自然会提出这样的问题:怎样选择核函数?核函数的性质会对学习机器的推广能力起决定作用吗?幸运的是,实验表明,采用不同种类核函数的学习机器表现出了大致相同的性能,它们找到的支持向量大致相同。多项式分类器、径向基函数、两层神经网络等都是常用的SVM的核函数。
首先将输入向量x通过映射Ψ:Rn→H映射到高维Hilbert空间H中。设核函数K满足:K(xi,xj)=Ψ(xi)·Ψ(xj)
则二次规划问题的目标函数变为:
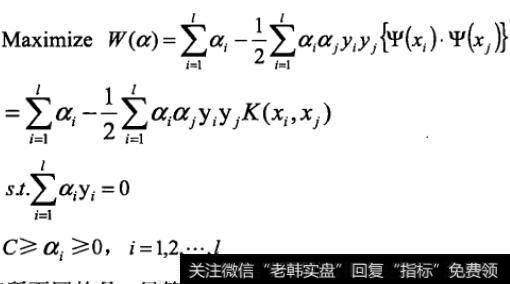
与线性情况有所不同的是:尽管在高维特征空间中线性判别面的法向量w仍可表示成这个空间中支持向量的线性组合,但由于将输入空间映射为高维空间的是非线性映射,这种线性组合关系在输入空间中不再表现为线性组合,我们又不可能把工作样本映射到高维空间再做判别,所以就需要重新考虑工作样本的决策问题。在训练完成之后,只需计算下列函数的符号即可:

式中,b作为偏移值,取值如下:
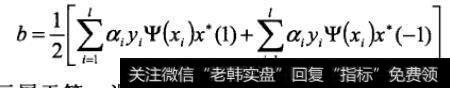
式中,x*(1)表示属于第一类的某个(任一个)支持向量:x*(-1)表示属于第二类的某个支持向量。
如果支持向量很多,则决策阶段的计算量也会较大。所以在实际应用中,如果训练集比较大而且得到的支持向量很多,在牺牲一点分类精度的情况下可以按一定规则舍弃一些支持向量来增加分类速度,这对时间有要求的实时系统是很有必要的。
通常,不需显式地知道Ψ和H,只需选择合适的核函数K就可以确定支持向量机。Mercer定理给出了核的数K满足上式的充要条件:
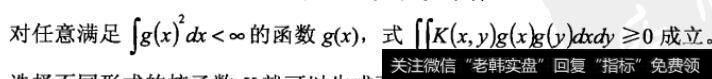
选择不同形式的核函数K就可以生成不同的支持向量机,常用的有以下几种:
(1)多项式SVM(d=1时候为线性核):K(x,y=[(x·Y)+1]d。
(2)径向基函数SVM: K(x,y)=e-‖x-y‖²/2σ²。
(3)Sigmoid函数SVM: K(x,y)=tanh(k(x·y)+δ)。
概括地说,支持向量机就是首先通过用内积函数定义的非线性变换将输入空间变换到一个高维空间,然后求(广义)最优分类面。SVM分类函数形式上类似于一个神经网络,输出的是若干中间层节点的线性组合,而每个中间层节点对应于输入样本与一个支持向量的内积,如图13-1所示。
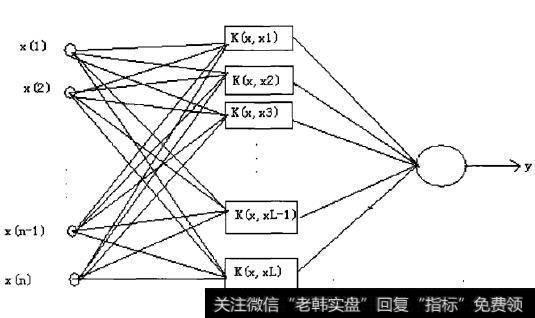
图13-1 支持向最机结构
其中输入层用于存储输入数据,并不做任何加工运算:中间层是通过对样本集的学习,选择K(X, Xi,),i=1,2,3,…,L;最后一层就是构造分类函数:
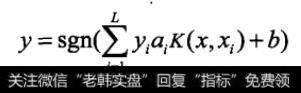
整个过程等价于在特征空间中构造一个最优超平面。
支持向量机的作用之一就是分类,根据分类的任务,可以划分为一分类、二分类及多分类。对于多类分类问题,可以用若干种手法将其分解为若干个二分类问题叠加。
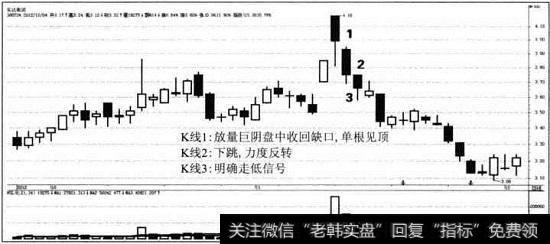
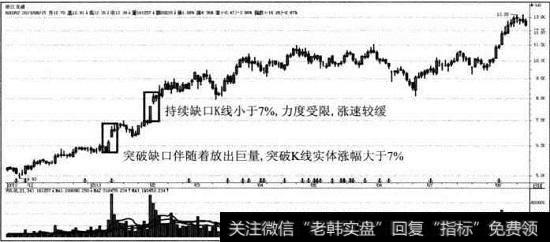
![[缺口镊什么]对缺口形态的解析](http://www.zcaijing.com/res/143961.jpg)
 2019-05-01
2019-05-01 ![[股票缺口理论]缺口理论选股法—缺口出现的原因、特性](http://www.zcaijing.com/res/140464.jpg)

![[突破性出血]突破性缺口、持续性缺口、测量缺口](http://www.zcaijing.com/res/127829.jpg)

![[股票缺口理论]缺口理论形态模型:跳跃各不同,陷阱和馅饼](http://www.zcaijing.com/res/118021.jpg)