支持向量机策略模型
支持向量机目前主要用来解决分类问题(如模式识别、判别分析)和回归问题,股市行为预测通常为预测股市数据的走势和预测股市数据的未来数值。
将走势看成两种状态(即涨、跌),问题便转化为分类的问题,一类是涨,一类是跌。而预测股市未来的价格是典型的回归问题,因此有理由相信支持向量机可以对股市进行预测。
1、择时模型设计的总体思路
择时模型必须具备记忆性、自学习性、容错性、快速易用性等特点,具体说明如下。
(1) 记忆性:对输入的样本数据具有存储功能,可随时调用、类比、验证。
(2) 自学习性:随着外部信息的增加,系统能不断学习新知识,并对其已有知识进行优化。
(3) 容错性:在输入样本数据不完备或带有嗓声的情况下,系统能得出较为准确的估算结果。
(4) 快速易用性:对用户具有友好的界面,能快速给出估算结果,且系统易于移植。
2、模型设计
利用SVM技术对股票价格进行预测主要包括训练数据准备、训练参数输入、学习样本输入、模型训练学习、评估训练结果、训练参数优化等一系列循环的过程,如图3-22所示。
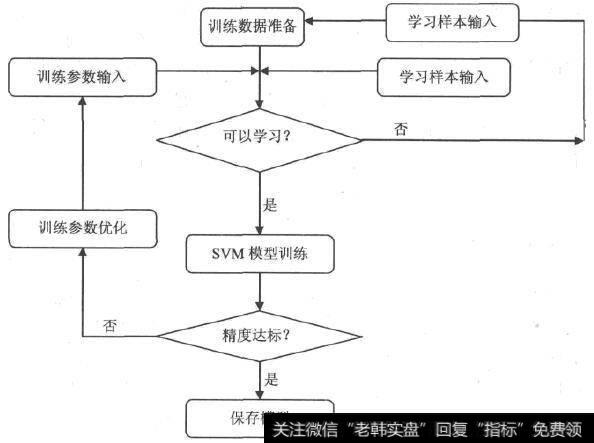
图3-22 基于SVM择时模型流程
(1) 在数据准备阶段主要是对预测指标的选定和已有历史数据资料的收集,并确定股票价格影响的输入向量。
(2) 训练参数输入阶段的任务主要是确定SVM模型的参数Y和Q(以RBF核函数为例)。如果是初次运行,则可以随意地预定义上述两个参数的值;但如果是重复运行多次,这时训练参数优化的步骤便开始起作用。
(3) 学习样本输入阶段的任务是将学习样本进行标准化,处理公式为:

其中,Xi不为xi分量的平均值,σ为Xi分量的标准差。在完成标准化工作后,将样本集任意地分为训练样本和测试样本,分别用于模型训练和精度检验。
(4)模型训练阶段包括:对输入的训练样本进行训练,得到模型的初始值a和b;然后利用上述算法提取出有效的、相关的数据点重新训练,得到最终的模型。
(5)训练结果评估阶段是对训练得出的模型推广(或称泛化)能力进行验证。所谓推广能力,是指经训练(学习)后的模型对未在训练集中出现的样本(即测试样本集)做出正确反应的能力,通常用平均平方误差(MSE)表示。
如果得出MSE结果较小,则说明该评估模型的推广能力强,或泛化能力强,否则就说明其推广能力较差。另外,也可以用平均绝对百分误差(MAPE)来衡量。当然还有很多其他的衡量指标,如误差绝对值的最大值、误差绝对值的平均值等。
择时问题本质上可以看做是一个分类问题,即将未来的走势分类为“涨”、“跌”两大类。SVM的一大优势就是解决了传统分类方法,如人工神经网络的次优陷阱问题,这使得SVM成为最近10年来最受关注的数学方法。
![[散户之家]散户制胜操作策略探索](http://www.zcaijing.com/res/146252.jpg)
 2019-07-30
2019-07-30 

![[一个普通猎人的工作日记]一个普通散户的炒股原则](http://www.zcaijing.com/res/145258.jpg)

![[连体形]箱体形态的操作策略及主要特征](http://www.zcaijing.com/res/144925.jpg)
![[股市止损37定律]止损是股市投资中关键理念](http://www.zcaijing.com/res/144725.jpg)